This section looks at abstract layers using an abstract data layer implementation. This type of abstraction can be very useful and is another step closer to Clean Architecture. Moreover, you can abstract almost anything this way, which is nothing more than applying the Dependency Inversion Principle (DIP).Let’s start with some context and the problem:
- The domain layer is where the logic lies.
- The UI links the user to the domain, exposing the features built into that domain.
- The data layer should be an implementation detail that the domain blindly uses.
- The data layer contains the code that knows where the data is stored, which should be irrelevant to the domain, but the domain directly depends on it.
The solution to break the tight coupling between the domain and the data persistence implementations is to create an additional abstract layer, as shown in the following diagram:
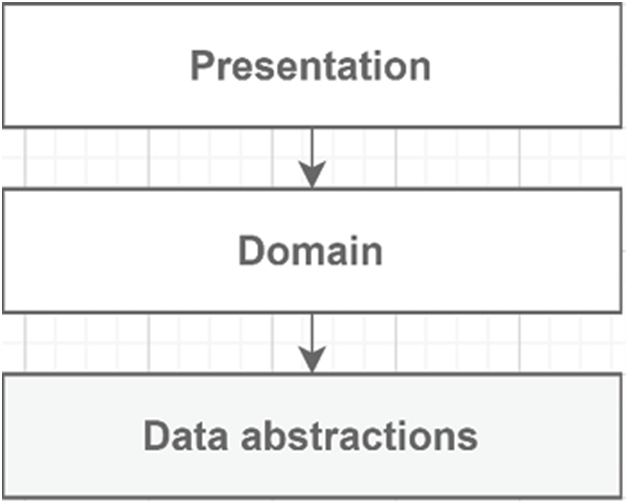
Figure 14.6: Replacing the data (persistence) layer with a data abstraction layer
New rule: only interfaces and data model classes go into the data abstractions layer. This new layer now defines our data access API and does nothing but expose a set of interfaces—the contract.Then, we can create one or more data implementations based on that abstract layer contract, like using EF Core. The link between the abstractions and implementations is done with dependency injection. The bindings defined in the composition root explain the indirect connection between the presentation and the data implementation.The new dependency tree looks like this:
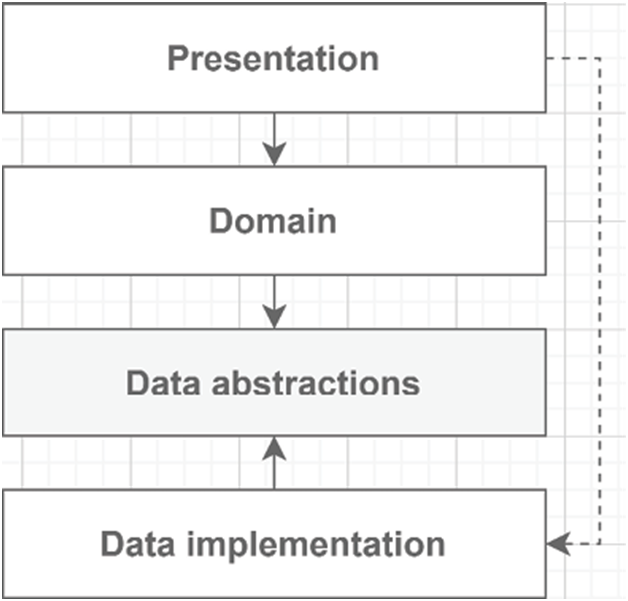
Figure 14.7: The relationships between layers
The presentation layer references a data implementation layer for the sole purpose of creating the DI bindings. We need those bindings to inject the correct implementation when creating domain classes. Besides, the presentation layer must not use the data layer’s abstractions or implementations.I created a sample project that showcases the relationships between the projects and the classes. However, that project would have added pages of code, so I decided not to include it in the book. The most important thing about abstract layers is the dependency flow between the layers, not the code itself.
The project is available on GitHub (https://adpg.link/s9HX).
In that project, the program injects an instance of the EF.ProductRepository class when a consumer asks for an object that implements the IProductRepository interface. In that case, the consuming class is ProductService and only depends on the IProductRepository interface. The ProductService class is unaware of the implementation itself: it leverages only the interface. The same goes for the program that loads a ProductService class but knows only about the IProductService interface. Here is a visual representation of that dependency tree:
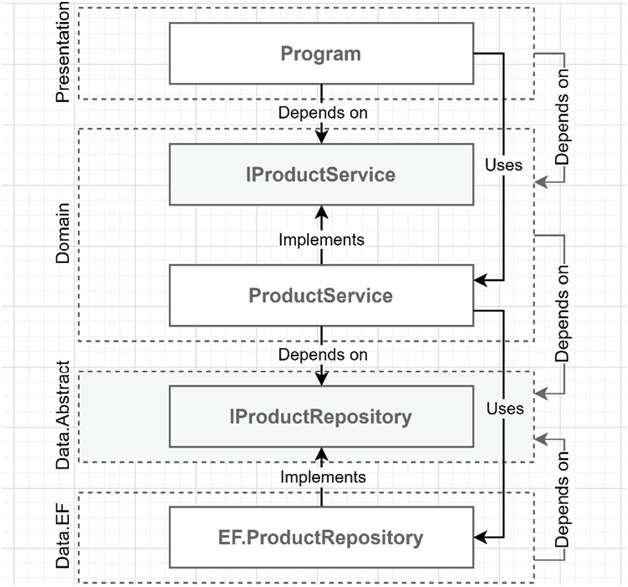
Figure 14.8: The dependency flow between layers, classes, and interfaces
In the preceding diagram, look at how dependencies converge on the Data.Abstract layer. The dependency tree ends up on that abstract data layer.With this applied piece of architectural theory, we are inverting the flow of dependencies on the data layer by following the DIP. We also cut out the direct dependency on EF Core, allowing us to implement a new data layer and swap it without impacting the rest of the application or update the implementation without affecting the domain. As I mentioned previously, swapping layers should not happen very often, if ever. Nonetheless, this is an important part of the evolution of layering, and more importantly, we can apply this technique to any layer or project, not just the data layer, so it is imperative to understand how to invert the dependency flow.
To test the APIs, you can use the Postman collection that comes with the book; visit https://adpg.link/postman8 or GitHub (https://adpg.link/net8) for more info.
Next, let’s explore sharing and persisting a rich domain model.